
This article focuses on Linux system calls and other low-level operations, such as the C library’s functions. System programming is the process of creating system software, which is low-level code that interacts directly with the kernel and core system libraries.
While files are the most basic abstraction in a Unix system, processes are the next most basic.
Processes are active, alive, and running applications that are executing object code. Processes, however, are made up of more than simply object code. They also include data, resources, state, and a virtualized computer.
Interprocess Communication
One fundamental function of an operating system is to allow processes to share information and notify each other of events. To coordinate their actions, processes interact with each other and with the kernel.
A process can have one or more execution threads, which are sequences of executable instructions: a single-threaded process has only one thread, whereas a multi-threaded process has several threads. Although some current languages advocate a more disciplined approach, such as the usage of thread-safe channels, threads within a process can communicate directly through shared memory.
There are numerous ways to launch processes that then communicate with each other and exchange various types of data. However, the underlying mechanism is the system called function called a fork. It spawns another child process that is an identical clone of the calling process till the point where the fork was called. After that, the forked processes can communicate data, events, statuses, etc. via various inter-process communication mechanisms that will be detailed in the following.
IPC mechanisms supported by Linux include:
- Pipes (named and unnamed)
- Message queues
- Shared files
- Shared memory semaphores
cPipes
All of the common Linux shells support redirection. For example:
$ ls | pr | lpr
Pipes the output from the ls command listing the directory’s files into the standard input of
the pr command which paginates them. Finally, the standard output from the pr command is piped into the standard input of the lpr command which prints the results on the default printer.
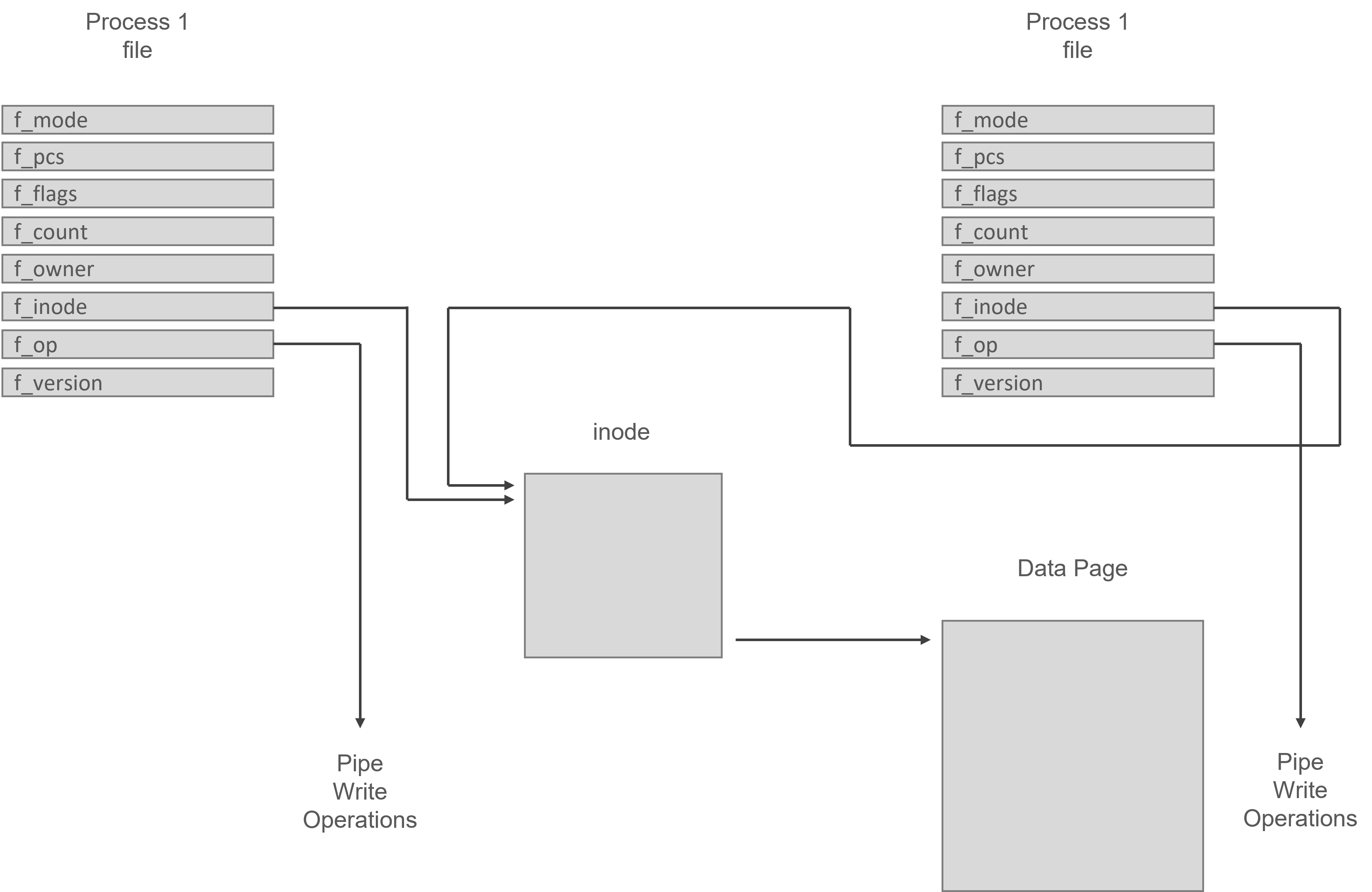
A pipe in Linux is made up of two file data structures that point to the same temporary VFS inode, which points to a physical page in memory. Each file data structure contains pointers to different file operation routine vectors; one for writing to the pipe, the other for reading from the pipe.
The general system calls read and write to regular files. Bytes are copied into the shared data page as the writing process writes to the pipe, and bytes are copied from the shared data page as the reading process reads from the pipe. Linux needs to synchronize pipe access. It uses locks, wait-for queues, and signals to ensure that the reader and writer of the pipe are on the same page.
The standard writing library functions are used by the writer to write to the pipe.
All of these pass file descriptors, which are indices into the process’s set of file data structures, each of which represents an open file or, in this example, an open pipe. The write routine pointed to by the file data structure representing this pipe is used by the Linux system call. Reading data from the pipe is a very similar process to writing it.
Non-blocking readings are allowed (depending on the mode in which the file or pipe was opened). An error will be returned if there is no data to be read or if the pipe is locked. This indicates that the process can continue.
Named pipes (often called FIFOs, short for “first in, first out”) are an interprocess communication (IPC) mechanism that provides a communication channel over a file descriptor, accessed via a special file. Regular pipes are used to “pipe” the output of one program into the input of another. They are produced in memory by a system call and are not stored on any filesystem. Named pipes function similarly to regular pipes, except they are accessible through a file known as a FIFO special file. This file can be accessed and communicated with by unrelated processes.
Message Queues
Message queues allow one or more processes to send messages to be read by one or more other processes. The msgque vector in Linux contains a list of message queues, each of which corresponds to a msqid ds data structure that completely specifies the message queue. A new msqid ds data structure is allocated from system memory and added to the vector when message queues are formed.
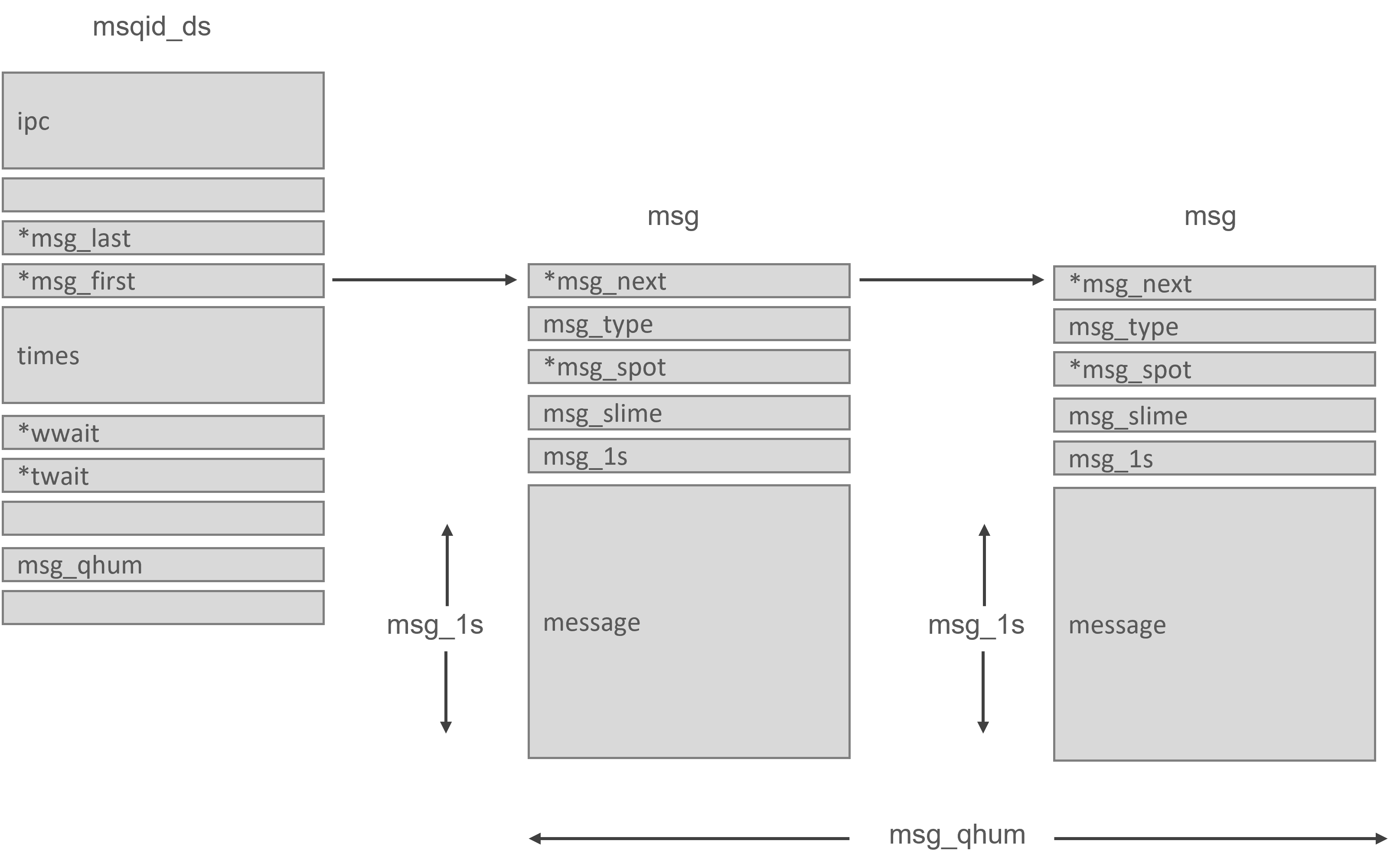
An IPC perm data structure and pointers to the messages entered onto this queue are included in each msqid_ds data structure. Linux also keeps track of queue modification times, such as the last time this queue was updated, and so on. The msqid ds also has two wait queues: one for message queue writers and another for message queue readers.
When a process tries to write a message to the write queue, the effective user and group identifiers are compared to the mode in the IPC perm data structure of this queue. If the process can write to the queue, the message can be transferred from the process’s address space into a msg data structure and placed at the end of the queue. Each message has an application-specific type that has been agreed upon by the cooperating processes. However, because Linux limits the quantity and length of messages that can be written, there may not be enough room for the message.
The process will be added to the write wait queue for this message queue. The scheduler will be asked to choose a new process to run. When one or more messages from this message queue are read, it will be woken up.
Reading from the queue is a similar process.
Shared Files
Shared files may be the most basic IPC mechanism. Consider the relatively simple case in which one process (producer) creates and writes to a file. Another process (consumer) reads from the same file.
One clear challenge of employing this IPC mechanism is the possibility of a race condition. Both the producer and the consumer may have access to the file at the same time, leaving the outcome uncertain. To avoid a race condition, the file must be locked in such a way that a write operation does not clash with any other operation, whether it is a read or a write. The standard system library’s locking API can be summarized as follows:
● Before writing to a file, a producer should obtain an exclusive lock on it. Only one process can hold an exclusive lock at a time, preventing a race condition because no other process can access the file until the lock is released.
● Before reading from a file, a consumer should obtain at least a shared lock on it. A shared lock can be held by multiple readers at the same time, but no writer can access a file if even a single reader has a shared lock.
It is more efficient to use a shared lock. There is no reason to restrict other processes from reading a file and not modifying its contents if one process is doing so. Writing, on the other hand, plainly necessitates exclusive access to a file.
A utility function called fcntl is included in the standard I/O library. It can be used to inspect and manipulate both exclusive and shared locks on a file. The function works with a file descriptor, which is a non-negative integer number that identifies a file within a process.
The following example uses the fcntl function to expose API details:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FileName "data.dat"
#define DataString "Hello!\nHow are you?\n"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* FAILURE */
}
int main() {
struct flock secured;
secured.l_type = F_WRLCK; /* read/write */
secured.l_whence = SEEK_SET; /* base for seek offsets */
secured.l_start = 0; /* first byte in file */
secured.l_len = 0; /* 0 here means 'until EOF' */
secured.l_pid = getpid(); /* process id */
int fd; /* fd to identify a file within a process */
if ((fd = open(FileName, O_RDWR | O_CREAT, 0666)) < 0) /* -1 signals an error */
report_and_exit("open failed...");
if (fcntl(fd, F_SETLK, &secured) < 0) /* F_SETLK doesn't block, F_SETLKW does */
report_and_exit("fcntl failed to get lock...");
else {
write(fd, DataString, strlen(DataString)); /* populate data file */
fprintf(stderr, "Process %d has written to data file...\n", secured.l_pid);
}
/* Now release the lock explicitly. */
secured.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &secured) < 0)
report_and_exit("unlocking failed");
close(fd); /* close the file: would unlock if needed */
return 0; /* terminating the process would unlock as well */
}
Shared Memory Semaphores
A semaphore is a synchronization mechanism. It allows a contending process or thread to alter, monitor queries, and control shared system resources. It is also a solution to the race condition in a multiprocessing system. A race condition occurs when multiple processes try to access shared resources. If the multi-threaded feature is needed by the application, then it comes with a set of issues such as race conditions, deadlocks, and incorrect behavior of threads.
A semaphore is based on an internal count that offers two basic operations:
- Wait: Tests the value of the semaphore count, and waits if the value is less than or equal to 0. Otherwise, decrements the semaphore count.
- Post: Increments the semaphore count. If any process is blocked, one of those processes is awoken.
Boost. Interprocess offers the following semaphore types:
#include <boost/interprocess/sync/interprocess_semaphore.hpp>
● interprocess_semaphore: An anonymous semaphore that can be placed in shared memory or memory-mapped files.
#include <boost/interprocess/sync/named_semaphore.hpp>
● named_semaphore: A named semaphore.
We’ll use shared memory to construct an integer array. It will be used to move data from one process to another.
The first process will write some integers to the array, and if the array is full, the process will block.
The second process will copy the transmitted data to its own buffer, blocking if there is no new data in the buffer.
This is the shared integer array (doc_anonymous_semaphore_shared_data.hpp):
#include <boost/interprocess/sync/interprocess_semaphore.hpp>
struct shmem_buff
{
enum { nr = 10 };
shmem_buff ()
: mutex(1), nempty(nr), nstored(0)
{}
//To protect and synchronize access, semaphores are used.
boost::interprocess::interprocess_semaphore
mutex, nempty, nstored;
//Things to be filled with
int stg[nr];
};
This is the process main process. Creates the shared memory, places there the integer array, and starts integers one by one, blocking if the array is full:
#include <boost/interprocess/shared_memory_object.hpp>
#include <boost/interprocess/mapped_region.hpp>
#include <iostream>
#include "doc_anonymous_semaphore_shared_data.hpp"
using namespace boost::interprocess;
int main ()
{
// On construction and destruction, remove shared memory
struct erase_sm
{
erase_sm() { shared_memory_object::remove("MySharedMemory"); }
~erase_sm(){ shared_memory_object::remove("MySharedMemory"); }
} remover;
//Make a shared memory object.
shared_memory_object obj
(create_only //only create
,"MySharedMemory" //name
,read_write //read-write mode
);
//Set size
obj.truncate(sizeof(shared_memory_buffer));
// In this process, map out the entire shared memory.
mapped_region region
(obj //What to map
,read_write // Read-write mapped
);
// Get the mapped region's address
void * addr = region.get_address();
//Build the shared structure in memory
shmem_buff * info = new (addr) shared_memory_buffer;
const int nr_msg = 100;
//Insert data in the array
for(int i = 0; i < nr_msg; ++i){
info->nempty.wait();
info->mutex.wait();
info->stg[i % shared_memory_buffer::nr] = i;
info->mutex.post();
info->nstored.post();
}
return 0;
}
The second process opens the shared memory and copies the received integers to it’s own buffer:
#include <boost/interprocess/shared_memory_object.hpp>
#include <boost/interprocess/mapped_region.hpp>
#include <iostream>
#include "doc_anonymous_semaphore_shared_data.hpp"
using namespace boost::interprocess;
int main ()
{
//On destruction, shared memory has to be removed
struct erase_sm
{
~erase_sm(){ shared_memory_object::remove("MySharedMemory"); }
} remover;
//Create a shared memory object.
shared_memory_object obj
(open_only //just create
,"MySharedMemory" //the name
,read_write //read-write mode
);
// In this process, map out the entire shared memory.
mapped_region region
(obj //What to map
,read_write //Map it as read-write
);
// Obtain the mapped region's address
void * addr = region.get_address();
//Get the shared structure
shmem_buff * info = static_cast<shared_memory_buffer*>(addr);
const int nr_msg = 100;
int extracted_info [nr_msg];
//Extract the information
int i;
for( i = 0; i < nr_msg; ++i){
info->nstored.wait();
info->mutex.wait();
extracted_info[i] = info->stg[i % shared_memory_buffer::nr];
info->mutex.post();
info->nempty.post();
}
return 0;
}
The same interprocess communication can be achieved with condition variables and mutexes. For several synchronization patterns, a semaphore is more efficient than a mutex/condition combination.
Linux systems provide two separate APIs for shared memory: the legacy System V API and the more recent POSIX one. These APIs should never be mixed in a single application, however. A downside of the POSIX approach is that features are still in development and dependent upon the installed kernel version, which impacts code portability
See other articles:

Accelerator Pedal Simulator for Acoustics Tuning
Have you ever wondered how the perfect roar of an engine, or the smooth hum of a luxury car is crafted? It all comes

Industrial Data Acquisition System
We’re excited to unveil one of our flagship products: an efficient and secure Data Acquisition System (DAS). Our team has designed this solution to

Optimizing our Custom Motor Controller for Motion Control
Using our carefully designed board, we demonstrate the impressive power and flexibility of integrating modern technologies into motor controllers. In the realm of small

What it means to make an efficient Battery Management System?
Digital Gate is excited to introduce you to one of our flagship products: an efficient and secure Battery Management System (BMS), meticulously designed and

Embedded World 2024
DigitalGate is excited to announce its forthcoming participation at Embedded World 2024 taking place in Nuremberg from the 9th to the 11th of April.

Capacitance Preservation: Strategies for DC Bias in MLCCs
Is the capacitance of the capacitor always same? Multilayer ceramic capacitors (MLCCs) offer several advantages that make them a popular choice for various electronic