
Dieser Artikel konzentriert sich auf Linux-Systemaufrufe und andere Low-Level-Operationen, wie zum Beispiel die Funktionen der C-Bibliothek. Systemprogrammierung ist der Prozess der Erstellung von Systemsoftware, d. h. Low-Level-Code, der direkt mit dem Kernel und den Kernsystembibliotheken interagiert.
Während Dateien die grundlegendste Abstraktion in einem Unix-System sind, sind Prozesse die nächst grundlegendere.
Prozesse sind aktive, lebendige und laufende Anwendungen, die Objektcode ausführen. Prozesse bestehen jedoch aus mehr als nur Objektcode. Sie beinhalten auch Daten, Ressourcen, Status und einen virtualisierten Computer.
Interprozesskommunikation
Eine grundlegende Funktion eines Betriebssystems besteht darin, dass Prozesse Informationen austauschen und sich gegenseitig über Ereignisse informieren können. Um ihre Aktionen zu koordinieren, interagieren Prozesse untereinander und mit dem Kernel.
Ein Prozess kann einen oder mehrere Ausführungsthreads haben, d. h. Sequenzen von ausführbaren Anweisungen: ein Single-Thread-Prozess hat nur einen Thread, während ein Multi-Thread-Prozess mehrere Threads hat. Obwohl einige aktuelle Sprachen einen disziplinierteren Ansatz befürworten, wie z. B. die Verwendung von threadsicheren Kanälen, können Threads innerhalb eines Prozesses direkt über den gemeinsamen Speicher kommunizieren.
Es gibt zahlreiche Möglichkeiten, Prozesse zu starten, die dann miteinander kommunizieren und verschiedene Arten von Daten austauschen. Der zugrundeliegende Mechanismus ist jedoch die sogenannte Systemfunktion, die als Fork bezeichnet wird. Es wird ein weiterer untergeordneter Prozess erzeugt, der ein identischer Klon des aufrufenden Prozesses bis zu dem Punkt ist, an dem der Fork aufgerufen wurde. Danach können die verzweigten Prozesse Daten, Ereignisse, Zustände usw. über verschiedene Kommunikationsmechanismen zwischen den Prozessen austauschen, die im Folgenden näher erläutert werden.
Zu den von Linux unterstützten IPC-Mechanismen gehören:
- Pipes (benannte und unbenannte)
- Nachrichten-Warteschlangen
- Gemeinsam genutzte Dateien
- Semaphore für den gemeinsamen Speicher
cPipes
Alle gängigen Linux-Shells unterstützen die Umleitung. Beispiel:
$ ls | pr | lpr
Leitet die Ausgabe des Befehls Is, der die Dateien des Verzeichnisses auflistet, an die Standardeingabe des Befehls pr weiter, der sie paginiert. Schließlich wird die Standardausgabe des Befehls pr über eine Pipe in die Standardeingabe des Befehls lpr geleitet, der die Ergebnisse auf dem Standarddrucker ausgibt.
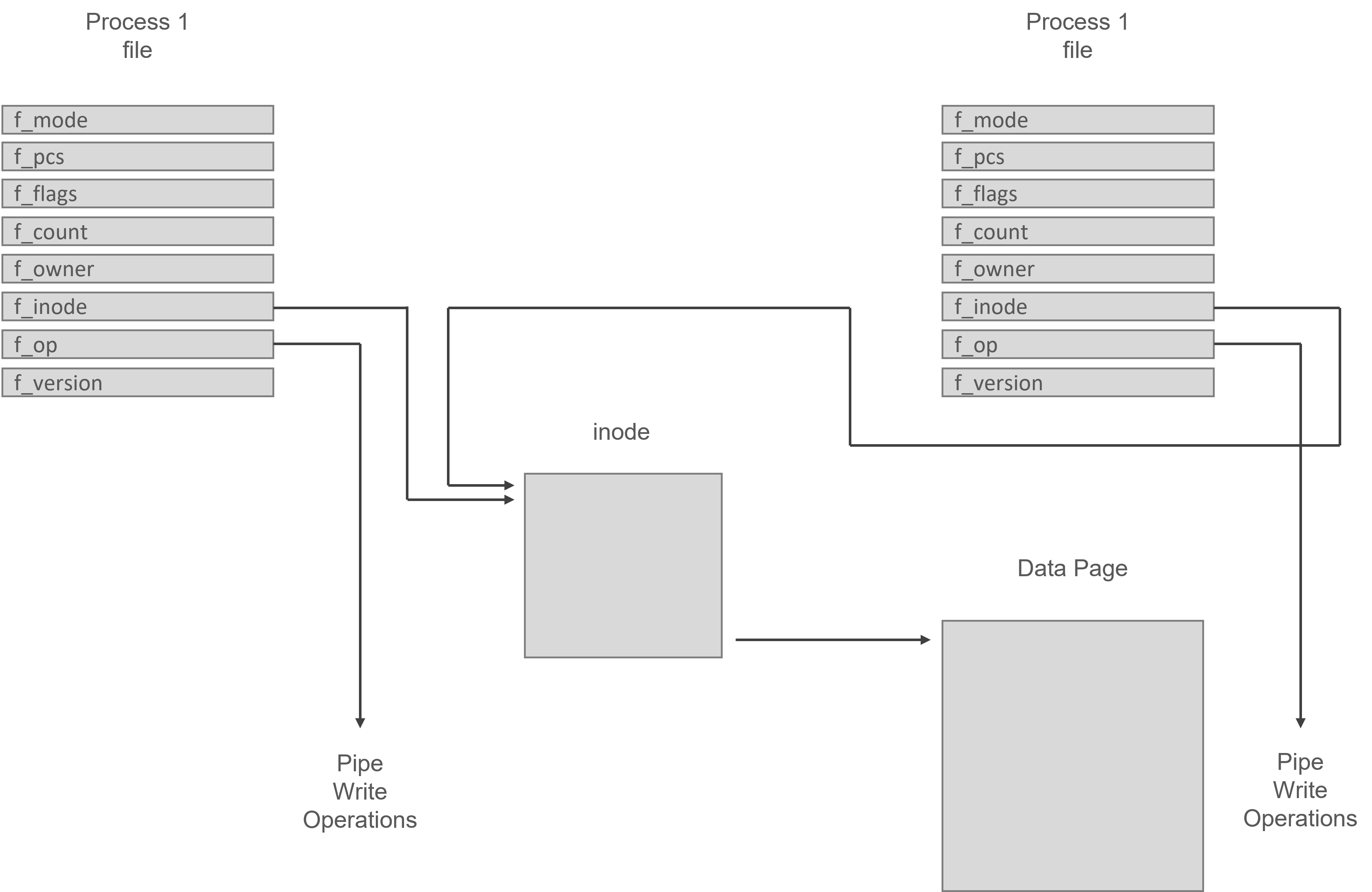
Eine Pipe in Linux besteht aus zwei Dateidatenstrukturen, die auf denselben temporären VFS-Inode zeigen, der auf eine physische Seite im Speicher verweist. Jede Dateidatenstruktur enthält Zeiger auf verschiedene Vektoren für Datei-Operationsroutinen; einer für das Schreiben in die Pipe, der andere für das Lesen aus der Pipe.
Die allgemeinen Systemaufrufe lesen und schreiben in reguläre Dateien. Bytes werden in die gemeinsame Datenseite kopiert, wenn der schreibende Prozess in die Pipe schreibt, und Bytes werden aus der gemeinsamen Datenseite kopiert, wenn der lesende Prozess aus der Pipe liest. Linux muss den Pipe-Zugriff synchronisieren. Es verwendet Sperren, Warteschlangen und Signale, um sicherzustellen, dass der Leser und der Schreiber der Pipe auf derselben Seite stehen.
Die Standardfunktionen der Schreibbibliothek werden vom Writer verwendet, um in die Pipe zu schreiben.
Alle diese Funktionen übergeben Dateideskriptoren, die Indizes in den Dateidatenstrukturen des Prozesses sind, von denen jede eine offene Datei oder, in diesem Beispiel, eine offene Pipe darstellt. Die Schreibroutine, auf die die Dateidatenstruktur, die diese Pipe repräsentiert, verweist, wird von dem Linux-Systemaufruf verwendet. Das Lesen von Daten aus der Pipe ist ein sehr ähnlicher Vorgang wie das Schreiben von Daten.
Nicht-blockierende Lesevorgänge sind zulässig (je nach dem Modus, in dem die Datei oder die Pipe geöffnet wurde). Ein Fehler wird zurückgegeben, wenn keine Daten zu lesen sind oder die Pipe gesperrt ist. Dies zeigt an, dass der Prozess fortgesetzt werden kann.
Named Pipes (oft FIFOs genannt, kurz für „first in, first out") sind ein Mechanismus für die Interprozesskommunikation (IPC), der einen Kommunikationskanal über einen Dateideskriptor bereitstellt, auf den über eine spezielle Datei zugegriffen wird. Reguläre Pipes werden verwendet, um die Ausgabe eines Programms in die Eingabe eines anderen zu „leiten". Sie werden durch einen Systemaufruf im Speicher erzeugt und nicht in einem Dateisystem gespeichert. Benannte Pipes funktionieren ähnlich wie reguläre Pipes, nur dass der Zugriff auf sie über eine Datei erfolgt, die als FIFO-Spezialdatei bekannt ist. Auf diese Datei kann von anderen Prozessen zugegriffen und mit ihr kommuniziert werden.
Nachrichten-Warteschlangen
Nachrichtenwarteschlangen ermöglichen es einem oder mehreren Prozessen, Nachrichten zu senden, die von einem oder mehreren anderen Prozessen gelesen werden können. Der msgque-Vektor in Linux enthält eine Liste von Nachrichten-Warteschlangen, von denen jede einer msqid-ds-Datenstruktur entspricht, die die Nachrichten-Warteschlange vollständig spezifiziert. Eine neue Datenstruktur msqid ds wird aus dem Systemspeicher zugewiesen und dem Vektor hinzugefügt, wenn Nachrichtenwarteschlangen gebildet werden.
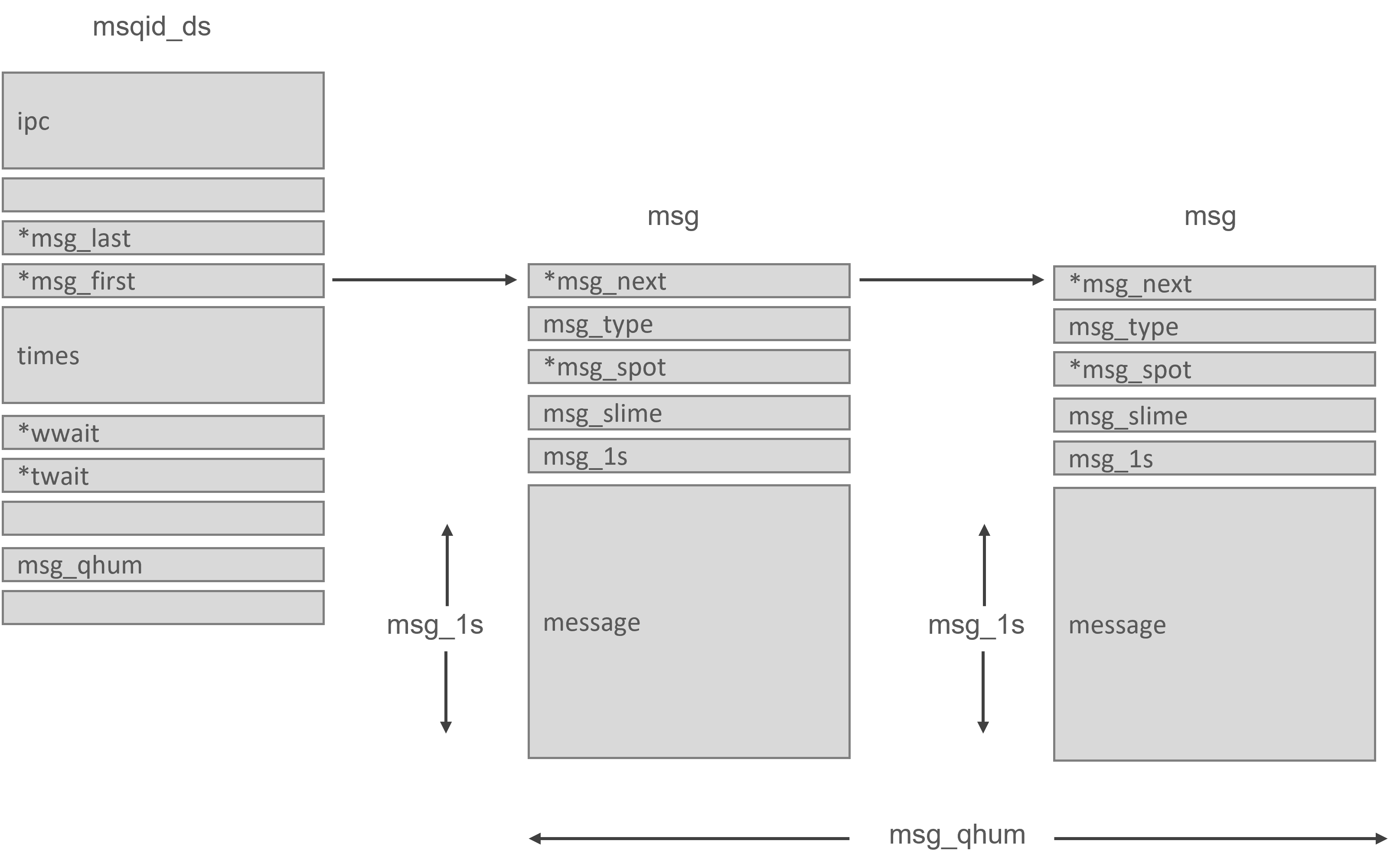
Jede msqid_ds-Datenstruktur enthält eine IPC-Perm-Datenstruktur und Zeiger auf die in diese Warteschlange eingegebenen Nachrichten. Linux merkt sich auch die Änderungszeiten der Warteschlangen, z. B. wann diese Warteschlange das letzte Mal aktualisiert wurde usw. Die msqid ds verfügt außerdem über zwei Warteschlangen: eine für die Schreiber von Nachrichtenwarteschlangen und eine für die Leser von Nachrichtenwarteschlangen.
Wenn ein Prozess versucht, eine Nachricht in die Schreibwarteschlange zu schreiben, werden die effektiven Benutzer- und Gruppenidentifikatoren mit dem Modus in der IPC-Perm-Datenstruktur dieser Warteschlange verglichen. Wenn der Prozess in die Warteschlange schreiben kann, kann die Nachricht aus dem Adressraum des Prozesses in eine msg-Datenstruktur übertragen und an das Ende der Warteschlange gestellt werden. Jede Nachricht hat einen anwendungsspezifischen Typ, auf den sich die kooperierenden Prozesse geeinigt haben. Da Linux jedoch die Anzahl und Länge der Nachrichten, die geschrieben werden können, begrenzt, ist möglicherweise nicht genügend Platz für die Nachricht vorhanden.
Der Prozess wird in die Warteschlange für das Schreiben dieser Nachricht aufgenommen. Der Scheduler wird aufgefordert, einen neuen Prozess auszuwählen, der ausgeführt werden soll. Wenn eine oder mehrere Nachrichten aus dieser Nachrichtenwarteschlange gelesen werden, wird sie aufgeweckt.
Das Lesen aus der Warteschlange ist ein ähnlicher Vorgang.
Gemeinsam genutzte Dateien
Gemeinsam genutzte Dateien sind vielleicht der einfachste IPC-Mechanismus. Betrachten wir den relativ einfachen Fall, in dem ein Prozess (Hersteller) eine Datei erstellt und in sie schreibt. Ein anderer Prozess (Verbraucher) liest aus derselben Datei.
Eine eindeutige Herausforderung bei der Verwendung dieses IPC-Mechanismus ist die Möglichkeit einer Wettlaufsituation. Sowohl der Hersteller als auch der Verbraucher können gleichzeitig Zugriff auf die Datei haben, sodass der Ausgang ungewiss ist. Um eine Race Condition zu vermeiden, muss die Datei so gesperrt werden, dass ein Schreibvorgang nicht mit einem anderen Vorgang kollidiert, egal ob es sich um einen Lese- oder Schreibvorgang handelt. Die Sperr-API der Standard-Systembibliothek lässt sich wie folgt zusammenfassen:
● Vor dem Schreiben in eine Datei sollte ein Producer eine exklusive Sperre auf die Datei erhalten. Eine exklusive Sperre kann jeweils nur von einem Prozess gehalten werden, wodurch eine Wettlaufsituation verhindert wird, da kein anderer Prozess auf die Datei zugreifen kann, bevor die Sperre nicht freigegeben ist.
● Vor dem Lesen einer Datei sollte ein Verbraucher zumindest eine gemeinsame Sperre für die Datei erhalten. Eine gemeinsame Sperre kann von mehreren Lesern gleichzeitig gehalten werden, aber kein Schreiber kann auf eine Datei zugreifen, wenn auch nur ein einziger Leser eine gemeinsame Sperre hat.
Es ist effizienter, eine gemeinsame Sperre zu verwenden. Es gibt keinen Grund, andere Prozesse daran zu hindern, eine Datei zu lesen und ihren Inhalt nicht zu verändern, wenn ein Prozess dies tut. Zum Schreiben hingegen ist ein exklusiver Zugriff auf eine Datei erforderlich.
Eine Utility-Funktion namens fcntl ist in der Standard-E/A-Bibliothek enthalten. Es kann verwendet werden, um sowohl exklusive als auch gemeinsam genutzte Sperren für eine Datei zu untersuchen und zu manipulieren. Die Funktion arbeitet mit einem Dateideskriptor, der eine nicht-negative ganze Zahl ist, die eine Datei innerhalb eines Prozesses identifiziert.
Das folgende Beispiel verwendet die Funktion fcntl, um API-Details offenzulegen:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FileName "data.dat"
#define DataString "Hello!\nHow are you?\n"
void report_and_exit(const char* msg) {
perror(msg);
exit(-1); /* FAILURE */
}
int main() {
struct flock secured;
secured.l_type = F_WRLCK; /* read/write */
secured.l_whence = SEEK_SET; /* base for seek offsets */
secured.l_start = 0; /* first byte in file */
secured.l_len = 0; /* 0 here means 'until EOF' */
secured.l_pid = getpid(); /* process id */
int fd; /* fd to identify a file within a process */
if ((fd = open(FileName, O_RDWR | O_CREAT, 0666)) < 0) /* -1 signals an error */
report_and_exit("open failed...");
if (fcntl(fd, F_SETLK, &secured) < 0) /* F_SETLK doesn't block, F_SETLKW does */
report_and_exit("fcntl failed to get lock...");
else {
write(fd, DataString, strlen(DataString)); /* populate data file */
fprintf(stderr, "Process %d has written to data file...\n", secured.l_pid);
}
/* Now release the lock explicitly. */
secured.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &secured) < 0)
report_and_exit("unlocking failed");
close(fd); /* close the file: would unlock if needed */
return 0; /* terminating the process would unlock as well */
}
Gemeinsam genutzte Speicher-Semaphoren
Eine Semaphore ist ein Synchronisationsmechanismus. Sie ermöglicht es einem konkurrierenden Prozess oder Thread, gemeinsame Systemressourcen zu verändern, Abfragen zu überwachen und zu kontrollieren. Es ist auch eine Lösung für die Race Condition in einem Multiprozessorsystem. Eine Race Condition tritt auf, wenn mehrere Prozesse versuchen, auf gemeinsame Ressourcen zuzugreifen. Wenn die Multithreading-Funktion von der Anwendung benötigt wird, bringt sie eine Reihe von Problemen mit sich, wie z. B. Race Conditions, Deadlocks und falsches Verhalten von Threads.
Eine Semaphore basiert auf einem internen Zähler, der zwei grundlegende Operationen bietet:
- Warten: Prüft den Wert der Semaphorenzählung und wartet, wenn der Wert kleiner oder gleich 0 ist, andernfalls wird die Semaphorenzählung dekrementiert.
- Posten: Erhöht den Semaphorenzähler. Wenn ein Prozess blockiert ist, wird einer dieser Prozesse geweckt.
Boost. Interprocess bietet die folgenden Semaphore-Typen:
#include <boost/interprocess/sync/interprocess_semaphore.hpp>
● interprocess_semaphore: Ein anonymer Semaphor, der im gemeinsamen Speicher oder in Speicher zugeordneten Dateien platziert werden kann.
#include <boost/interprocess/sync/named_semaphore.hpp>
● named_semaphore: Eine benannte Semaphore.
Wir werden den gemeinsamen Speicher verwenden, um ein Integer-Array zu erstellen. Sie wird verwendet, um Daten von einem Prozess zu einem anderen zu übertragen.
Der erste Prozess schreibt einige Ganzzahlen in das Array und wenn das Array voll ist, wird der Prozess blockiert.
Der zweite Prozess kopiert die übertragenen Daten in seinen eigenen Puffer und blockiert, wenn sich keine neuen Daten im Puffer befinden.
Dies ist das gemeinsam genutzte Integer-Array (doc_anonymous_semaphore_shared_data.hpp):
#include <boost/interprocess/sync/interprocess_semaphore.hpp>
struct shmem_buff
{
enum { nr = 10 };
shmem_buff ()
: mutex(1), nempty(nr), nstored(0)
{}
//To protect and synchronize access, semaphores are used.
boost::interprocess::interprocess_semaphore
mutex, nempty, nstored;
//Things to be filled with
int stg[nr];
};
Dies ist der Prozess, Hauptprozess. Erzeugt den gemeinsamen Speicher, legt dort das Integer-Array ab und startet die Integer nacheinander, wobei er blockiert, wenn das Array voll ist:
#include <boost/interprocess/shared_memory_object.hpp>
#include <boost/interprocess/mapped_region.hpp>
#include <iostream>
#include "doc_anonymous_semaphore_shared_data.hpp"
using namespace boost::interprocess;
int main ()
{
// On construction and destruction, remove shared memory
struct erase_sm
{
erase_sm() { shared_memory_object::remove("MySharedMemory"); }
~erase_sm(){ shared_memory_object::remove("MySharedMemory"); }
} remover;
//Make a shared memory object.
shared_memory_object obj
(create_only //only create
,"MySharedMemory" //name
,read_write //read-write mode
);
//Set size
obj.truncate(sizeof(shared_memory_buffer));
// In this process, map out the entire shared memory.
mapped_region region
(obj //What to map
,read_write // Read-write mapped
);
// Get the mapped region's address
void * addr = region.get_address();
//Build the shared structure in memory
shmem_buff * info = new (addr) shared_memory_buffer;
const int nr_msg = 100;
//Insert data in the array
for(int i = 0; i < nr_msg; ++i){
info->nempty.wait();
info->mutex.wait();
info->stg[i % shared_memory_buffer::nr] = i;
info->mutex.post();
info->nstored.post();
}
return 0;
}
Der zweite Prozess öffnet den gemeinsamen Speicher und kopiert die empfangenen Ganzzahlen in seinen eigenen Puffer:
#include <boost/interprocess/shared_memory_object.hpp>
#include <boost/interprocess/mapped_region.hpp>
#include <iostream>
#include "doc_anonymous_semaphore_shared_data.hpp"
using namespace boost::interprocess;
int main ()
{
//On destruction, shared memory has to be removed
struct erase_sm
{
~erase_sm(){ shared_memory_object::remove("MySharedMemory"); }
} remover;
//Create a shared memory object.
shared_memory_object obj
(open_only //just create
,"MySharedMemory" //the name
,read_write //read-write mode
);
// In this process, map out the entire shared memory.
mapped_region region
(obj //What to map
,read_write //Map it as read-write
);
// Obtain the mapped region's address
void * addr = region.get_address();
//Get the shared structure
shmem_buff * info = static_cast<shared_memory_buffer*>(addr);
const int nr_msg = 100;
int extracted_info [nr_msg];
//Extract the information
int i;
for( i = 0; i < nr_msg; ++i){
info->nstored.wait();
info->mutex.wait();
extracted_info[i] = info->stg[i % shared_memory_buffer::nr];
info->mutex.post();
info->nempty.post();
}
return 0;
}
Die gleiche prozessübergreifende Kommunikation kann mit Zustandsvariablen und Mutexen erreicht werden. Bei mehreren Synchronisationsmustern ist eine Semaphore effizienter als eine Mutex/Condition-Kombination.
Linux-Systeme bieten zwei getrennte APIs für gemeinsamen Speicher: die alte System-V-API und die neuere POSIX-API. Diese APIs sollten jedoch nie in einer einzigen Anwendung gemischt werden. Ein Nachteil des POSIX-Ansatzes ist, dass sich die Funktionen noch in der Entwicklung befinden und von der installierten Kernelversion abhängen, das die Portabilität des Codes beeinträchtigt.
Weitere Artikel anschauen:

Accelerator Pedal Simulator for Acoustics Tuning
Have you ever wondered how the perfect roar of an engine, or the smooth hum of a luxury car is crafted? It all comes

Industrial Data Acquisition System
We’re excited to unveil one of our flagship products: an efficient and secure Data Acquisition System (DAS). Our team has designed this solution to

Optimizing our Custom Motor Controller for Motion Control
Using our carefully designed board, we demonstrate the impressive power and flexibility of integrating modern technologies into motor controllers. In the realm of small

What it means to make an efficient Battery Management System?
Digital Gate is excited to introduce you to one of our flagship products: an efficient and secure Battery Management System (BMS), meticulously designed and

Embedded World 2024
DigitalGate is excited to announce its forthcoming participation at Embedded World 2024 taking place in Nuremberg from the 9th to the 11th of April.

Kapazitätserhalt: Strategien für DC-Vorspannung in MLCCs
Ist die Kapazität des Kondensators immer gleich? Keramische Vielschichtkondensatoren (Multilayer Ceramic Capacitors, MLCCs) bieten eine Reihe von Vorteilen,